최수정
비정형 트래픽을 처리하는 서버리스 아키텍처를 설계하고,
실제 운영 중인 서비스를 구축·운영하고 있습니다.
보안을 고려한 인프라 설계와 자동화 기반 운영 효율화를 지향합니다.
부하 테스트 중 발생한 오류를 CloudWatch 로그 기반으로 추적하여
Lambda 런타임 및 네트워크 이슈를 해결하고 서비스 안정성을 개선했습니다.
카카오톡을 통해 자신만의 캐릭터 '말랑이'를 육성하는 게임형 챗봇 서비스입니다. 비정형 트래픽에 최적화된 서버리스 아키텍처로 설계하여 실제 운영 중입니다.
시스템 아키텍처
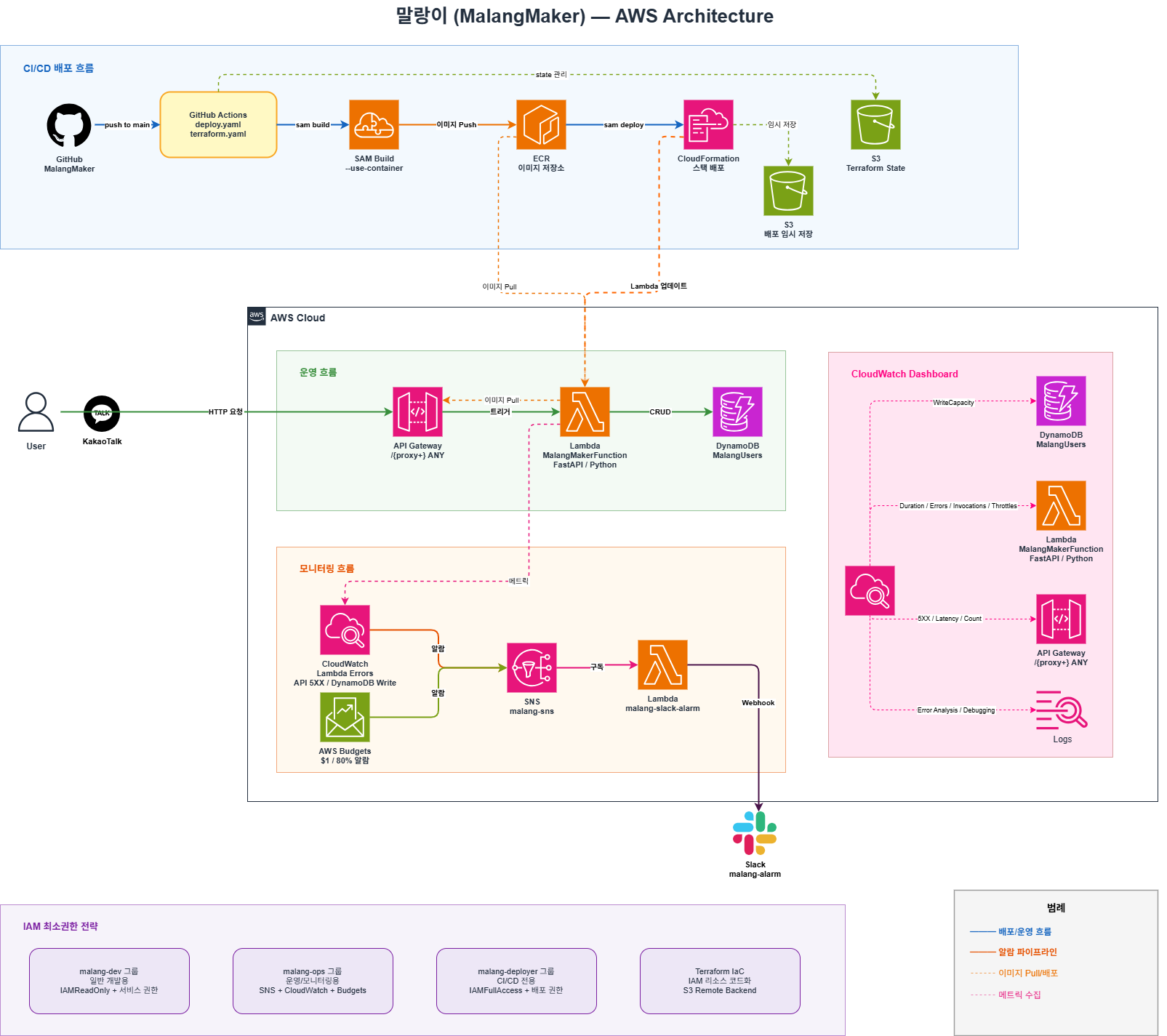
CI/CD 배포 흐름 · 운영 흐름 · 모니터링 흐름 · IAM 최소권한 전략
테크 스택 및 설계 이유
terraform import로 가져와 코드화.
terraform plan으로 변경 사항 사전 검증 후 GitHub Actions에서 apply 실행
terraform plan 자동 검증으로 적용 전 확인자동화 배포 파이프라인
운영 현황 및 유지보수
| 항목 | 현황 |
|---|---|
| 운영 기간 | 2026.02 ~ 현재 |
| 사용자 | 지인 베타 운영 |
| 월 비용 | 0.03$ |
| 에러율 | 0% (CloudWatch 현재 기준) |
- ✅ CloudWatch: Lambda 실행 로그 수집 · 에러/5XX 알람
- ✅ SNS + Slack: 비용 초과 시 실시간 알림
- ✅ AWS Budgets: 월별 비용 임계값 0.03$ / 80% 설정
- 2026.02FastAPI 로컬 개발 → Lambda 서버리스 마이그레이션
- 2026.03CloudWatch 모니터링 추가
- 2026.03SNS 비용 알림 연동
- 2026.03Terraform IaC + GitHub Actions CI/CD 자동화
- 2026.03부하 테스트 중 KeyError 발견 후 예외처리 추가
- 2026.03 EventBridge 웜업 적용으로 Lambda 콜드스타트 개선
부하 테스트
서버리스 아키텍처의 특성상 트래픽 급증 및 콜드 스타트 상황에서의 안정성을 검증하기 위해 k6 기반 부하 테스트를 수행했습니다.
| 측정 항목 | 측정 방법 | 기대값 |
|---|---|---|
| 평균 응답시간 | k6 http_req_duration avg | 200ms 이내 |
| p95 응답시간 | k6 p(95) | 3,000ms 이내 |
| 에러율 | k6 http_req_failed | 5% 미만 |
| 콜드 스타트 지연 | k6 max + CloudWatch Duration Max | 측정값 확인 |
| Lambda 자동 스케일링 | CloudWatch Invocations | Throttle 미발생 |
| DynamoDB 스로틀링 | CloudWatch ConsumedWriteCapacity | 임계치 미달 |
| 지표 | 결과 |
|---|---|
| 평균 응답시간 | 45ms ✅ |
| p95 응답시간 | 63.84ms ✅ |
| 최대 응답시간 | 1.52s (콜드 스타트) |
| 에러율 | 6.62% ❌ → 버그 발견 |
| Lambda Errors | 0건 ✅ |
| Lambda Throttles | 0건 ✅ |
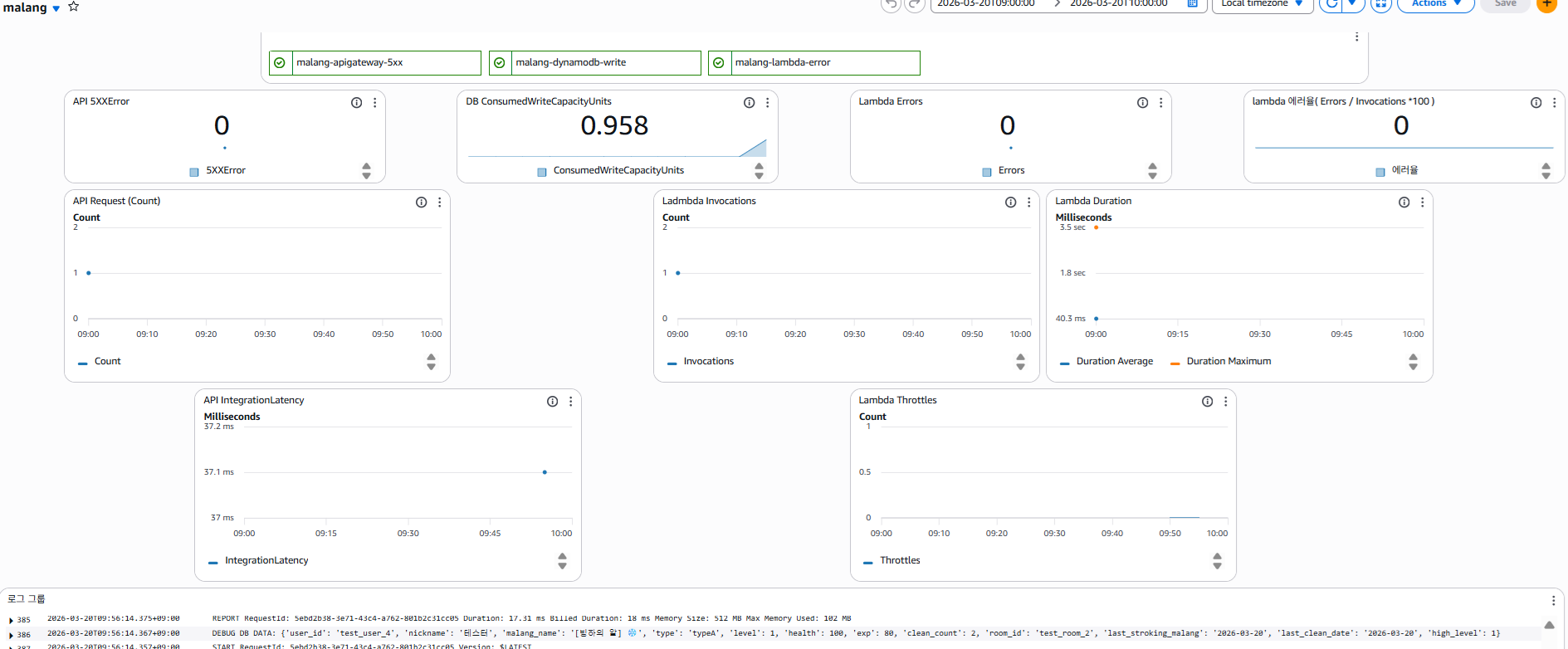
CloudWatch Logs 필터링으로 KeyError: 'none' 확인.
사망 상태(health: 0) 말랑이의
type이 "none"으로 저장된 유저에 대해 쓰다듬기 예외처리 누락.
사망 상태 체크 로직 추가 후 재배포. 부하 테스트로 실제 운영 버그를 발견하고 수정하는 사이클 경험.
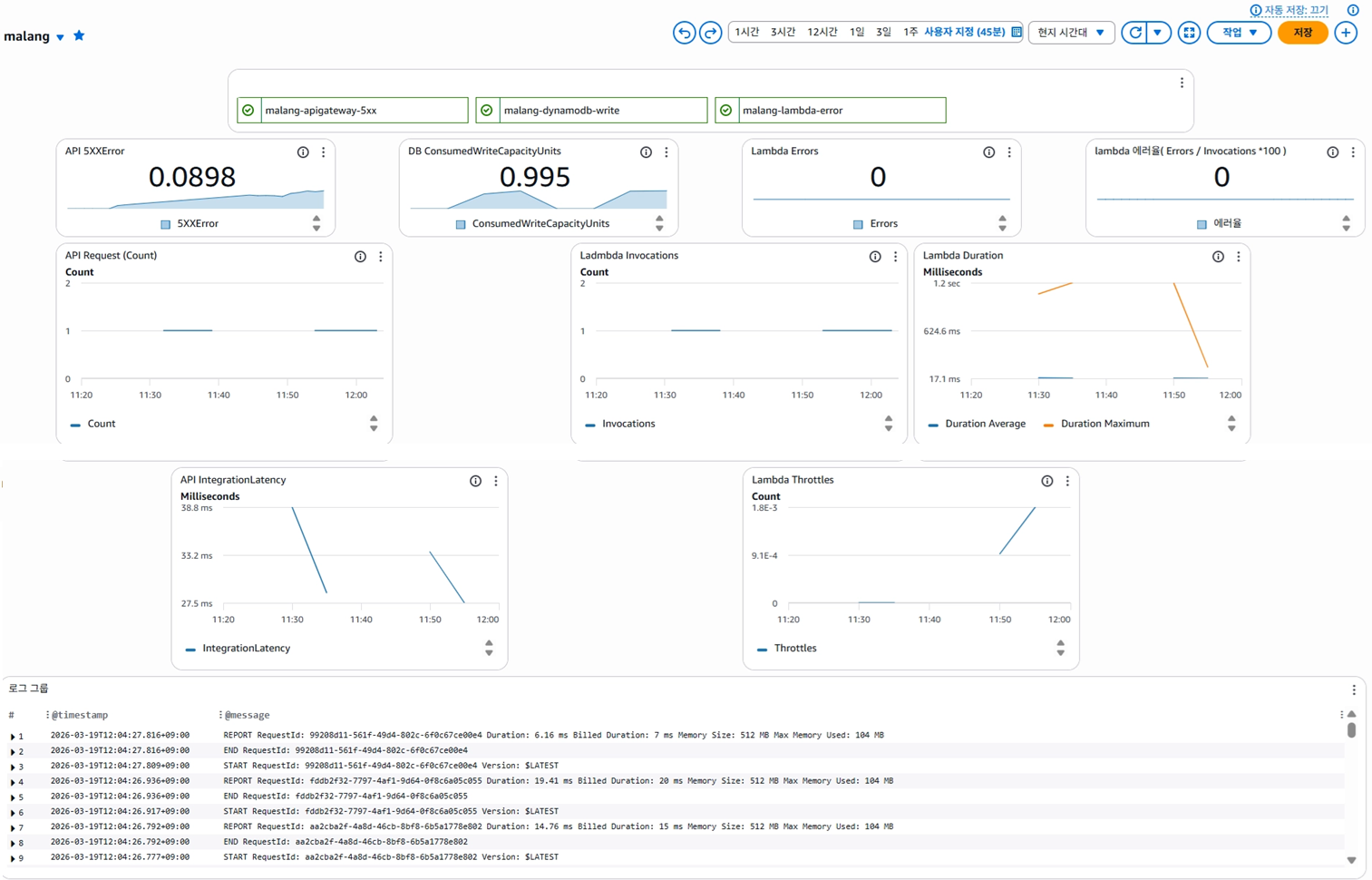
| 지표 | 쓰다듬기 | 똥치우기 |
|---|---|---|
| 평균 응답시간 | 50ms ✅ | 56ms ✅ |
| p95 응답시간 | 70ms ✅ | 75ms ✅ |
| 에러율 | 0% ✅ | 0% ✅ |
| Lambda Throttles | 미발생 ✅ | 미발생 ✅ |
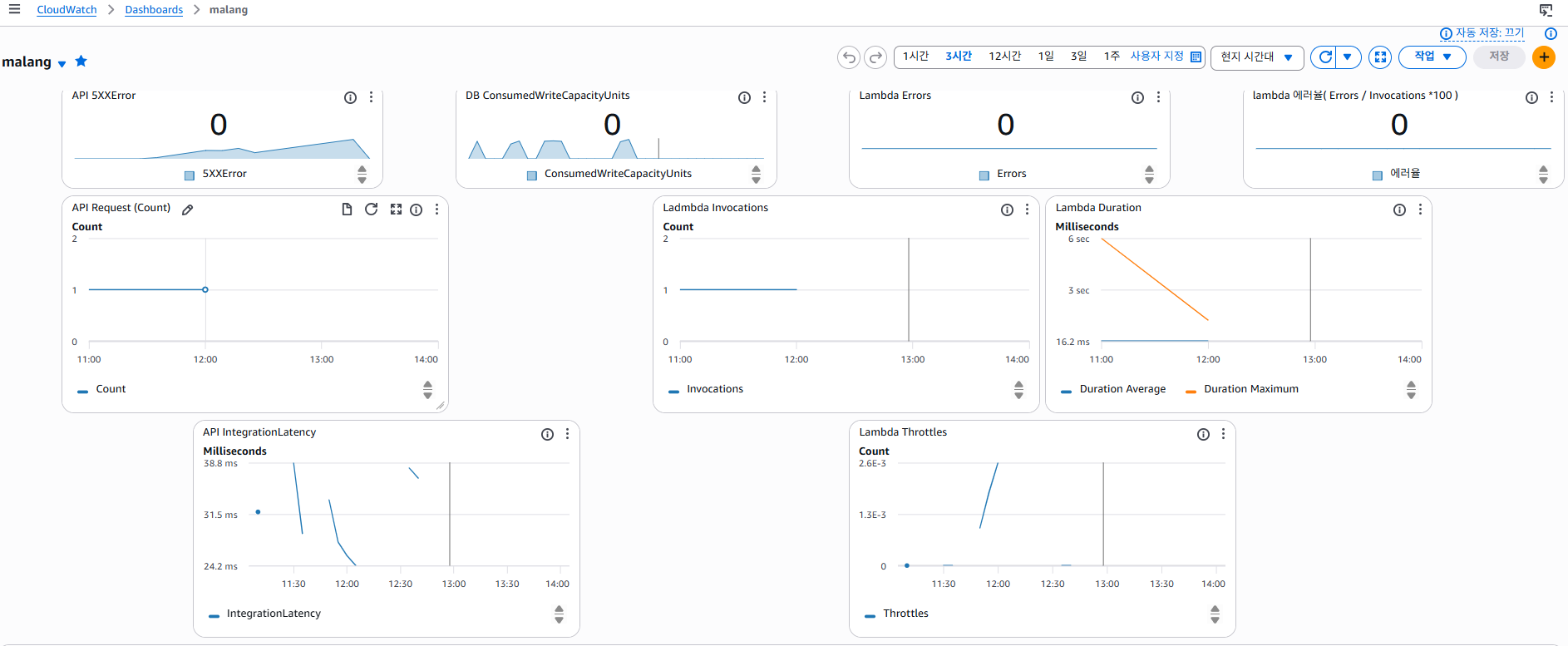
15분 유휴 후 첫 요청 최대 6s → 이후 16ms로 안정화. 서버리스 환경에서 콜드 스타트가 초기 지연에 영향을 미치지만 컨테이너 재사용으로 응답 속도가 빠르게 안정화됨을 확인.
| 지표 | 웜업 전 | 웜업 후 |
|---|---|---|
| 첫 요청 응답시간 | ~6000ms ❌ | < 100ms ✅ |
| p95 응답시간 | 73.12ms | 78.63ms |
| 최대 응답시간 | — | 284ms |
| 에러율 | 0% | 0% ✅ |
트러블슈팅 및 배운 점
카카오톡 메시지를 보내도 응답이 없고 '네트워크 오류'만 표시. 503 에러 코드조차 뜨지 않음.
원인일반 python:3.10-slim 이미지 사용. Lambda는 전용 런타임이 필요하며 Init 단계 자체가 실패해 카카오 측이 연결 거부로 판단.
FROM public.ecr.aws/lambda/python:3.10재발 방지
Lambda 컨테이너 이미지는 반드시 public.ecr.aws/lambda/ 베이스 이미지 사용. GitHub Actions deploy.yaml에 명시하여
수동 배포 실수 방지.
Lambda 내부 500대 에러 발생 시 카카오 측에서 연결 강제 종료. sam logs로 로그 직접 확인.
handler = Mangum(app, lifespan="off")재발 방지
CloudWatch Lambda Errors 알람 설정으로 에러 발생 즉시 Slack 알림 수신. 배포 후 에러율 모니터링 습관화.
기존 빌드 캐시(.aws-sam)가 오염된 상태로 올라간 것.
해결rmdir /s /q .aws-sam sam build --use-container sam deploy재발 방지
GitHub Actions에서 sam build를 자동화하여 로컬 캐시 문제 원천 제거. 수동 배포 프로세스 자체를 없앰.
AWS_REGION은 Lambda 런타임 예약 환경 변수. 사용자가 덮어쓰면 값이 무시되거나 충돌 경고 발생.
Variables: MY_APP_REGION: ap-northeast-2재발 방지
Lambda 예약 환경 변수 목록 숙지. AWS_ 접두사 환경변수 사용 시 공식 문서 확인 습관화.
GitHub Actions에서 terraform apply 시 IAM 유저/그룹 전부 EntityAlreadyExists 에러.
로컬 terraform.tfstate가 .gitignore로 미업로드. Actions가 빈 state에서 시작해 기존 리소스를 새로 만들려다 충돌.
backend "s3" {
bucket = "aws-sam-cli-managed-..."
key = "iam/terraform.tfstate"
}
terraform init -migrate-state
재발 방지
S3 Remote Backend로 state를 중앙 관리. 어떤 환경에서 실행해도 동일한 state 참조. PR 시 terraform plan 자동 검증으로
적용 전 확인.
terraform apply 시 AccessDeniedException: events:PutRule 에러. IAM 정책을 방금 추가했는데도 권한 없음.
Terraform이 IAM 정책 attachment와 EventBridge rule을 병렬로 실행. 정책이 완전히 적용되기 전에 PutRule 호출.
해결resource "aws_cloudwatch_event_rule" "warmup" {
depends_on = [aws_iam_group_policy_attachment.deployer]
}
재발 방지
IAM 정책 변경과 해당 권한을 사용하는 리소스가 함께 추가될 때는 항상 depends_on 명시.
부하 테스트에서 측정한 최대 6s의 콜드스타트 지연이 실제 사용자 입장에서는 응답이 없는 것처럼 느껴지는 경험으로 이어진다는 점을 직접 체감했습니다. 해결 방법을 찾는 과정에서 Provisioned Concurrency와 EventBridge 웜업을 비교했고, 비용 대비 효과를 고려해 웜업을 선택했습니다. 이 경험을 통해 서버리스 아키텍처는 비용 효율성과 응답 안정성 사이에 트레이드오프가 존재한다는 것을 체감했고, 트래픽 패턴이 안정적으로 바뀐다면 EC2 전환도 고려할 수 있다는 판단 기준을 갖게 되었습니다.
현재 Logs와 Metrics는 CloudWatch로 수집 중이지만, 요청이 Lambda 내부에서 어느 구간에서 지연되는지 추적하는 Tracing이 없습니다. AWS X-Ray를 도입하면 Lambda → DynamoDB 각 구간별 응답시간을 추적할 수 있어 병목 구간을 특정할 수 있습니다. 또한 챗봇 게임 특성상 자동화 매크로 사용이 쉬운 구조입니다. X-Ray로 엔드포인트별 호출 패턴을 분석하고, 비정상적인 요청이 집중되는 지점에 매크로 방지 로직을 적용하고 싶습니다.
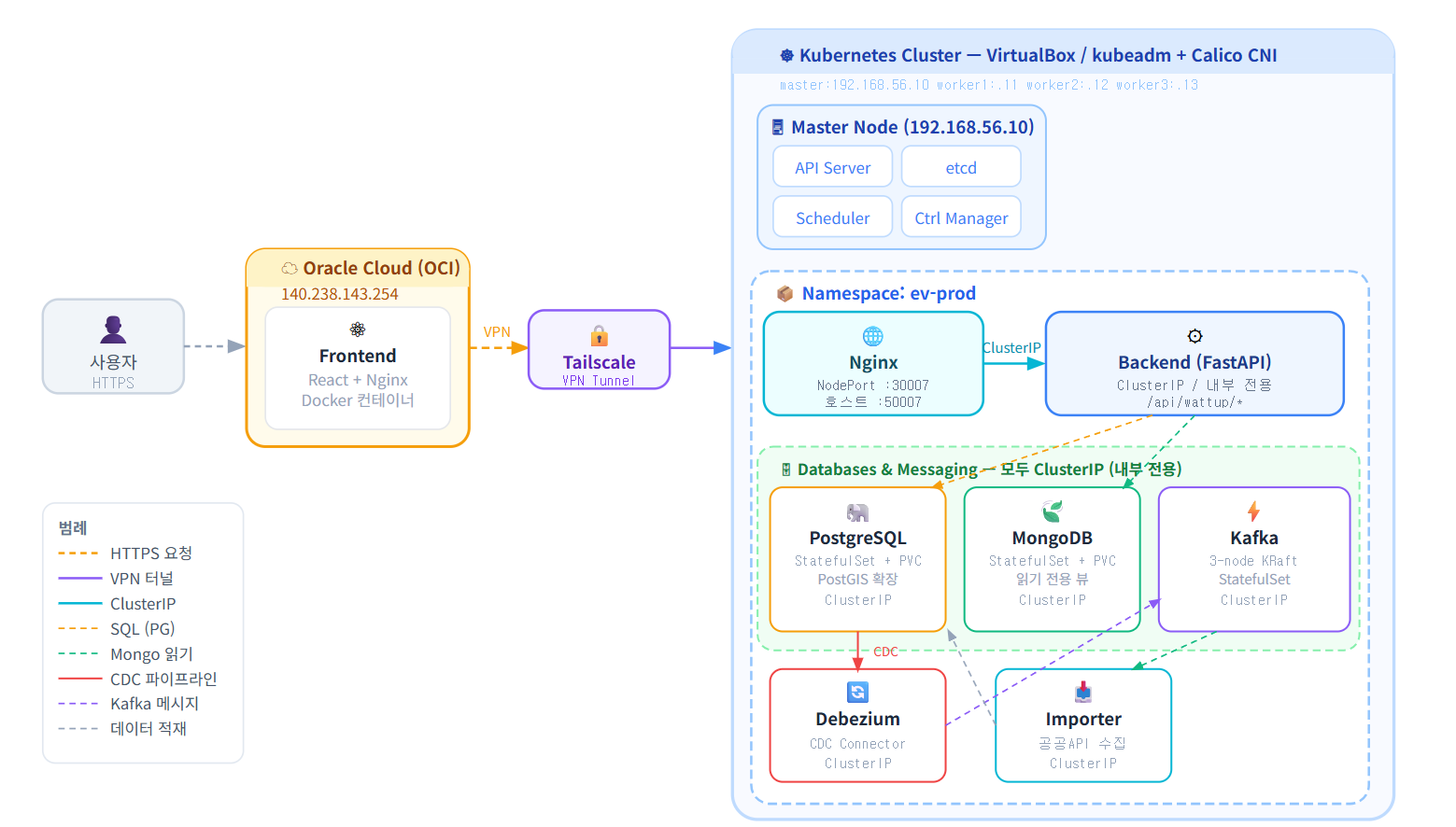
Wattup
전기차 충전소 실시간 예약 및 현황 관리 서비스. VirtualBox 기반 On-premise Kubernetes 클러스터를 설계·구축하고 프론트엔드 개발을 담당했습니다.
EKS 같은 관리형 서비스는 내부 동작을 추상화합니다. 스케줄링, 네트워킹, 스토리지를 직접 다뤄야 나중에 EKS도 제대로 쓸 수 있다고 판단했습니다. 또한 회사 환경에서는 비용 문제로 직접 구축하는 경우가 많습니다.
minikube는 단일 노드 실습용입니다. kubeadm으로 멀티 노드(master + worker 3개) 클러스터를 직접 구성하여 노드 간 네트워킹, pod 스케줄링, CNI 동작을 실제 환경에 가깝게 경험했습니다.
limits.memory는
OOM killer 상한이고 JVM의 -Xmx는 힙 크기로 별개 동작. JVM 컨테이너는 반드시 HEAP_OPTS와
limits.memory를 함께 설정해야 함.
local-path-provisioner가 PVC 디렉토리를 root 소유로 생성. runAsUser: 999를 함께 설정하면 오히려
권한이 없어짐.
securityContext: fsGroup: 999 # runAsUser, runAsGroup 제거재발 방지
StatefulSet 배포 시 securityContext 설정 가이드 문서화하여 팀 공유. fsGroup만 단독 사용 원칙 명시.
3-node KRaft는 과반수 노드가 동시에 떠야 리더 선출 가능. StatefulSet 기본 순차 실행으로 kafka-0 혼자 먼저 떠서 쿼럼 불가 → 데드락.
해결spec: podManagementPolicy: Parallel # headless Service publishNotReadyAddresses: true재발 방지
Kafka StatefulSet 배포 템플릿에 Parallel 설정을 기본값으로 포함. 트러블슈팅 문서에 KRaft 쿼럼 요구사항 명시.
Tailscale 설치 후 Calico가 tailscale0을 노드 IP로 착각 → CoreDNS / kube-proxy /
local-path-provisioner 연쇄 CrashLoop.
Calico IP 자동 감지가 Tailscale VPN 인터페이스를 우선 선택. Pod 네트워크 라우팅 전체 붕괴.
해결kubectl patch felixconfiguration default \
--type=merge \
-p '{"spec":{"ipv4DetectionMethod":"interface=enp0s8"}}'
sudo tailscale up --accept-routes=false
재발 방지
Tailscale 설치 SOP 문서화: ① felixconfiguration 패치 먼저 ② --accept-routes=false 옵션 필수 ③ 설치 후 전
노드 CNI 상태 확인. 팀 전체 공유.
DNAT 설정 후에도 SYN 패킷만 반복. SYN-ACK 없음 (tcpdump로 확인).
원인DNAT으로 요청은 worker3으로 전달되나 응답 패킷 출발지가 worker3 IP → 클라이언트가 예상 못한 IP로 판단 거부. MASQUERADE 누락.
해결sudo iptables -t nat -A PREROUTING -i tailscale0 \ -p tcp --dport 50007 -j DNAT \ --to-destination 192.168.56.13:30007 sudo iptables -t nat -A POSTROUTING \ -p tcp -d 192.168.56.13 --dport 30007 -j MASQUERADE재발 방지
iptables 설정 스크립트화 + netfilter-persistent save로 영구 저장. DNAT 설정 시 MASQUERADE 세트로 체크리스트화.
Vite는 빌드 타임에 환경변수를 JS 번들에 직접 삽입. 런타임 변경 불가. 기존 이미지에 학원 PC IP 하드코딩.
해결docker build --no-cache \ --build-arg VITE_API_URL=http://100.x.x.x:50007/api \ -t soojungchoi/wattup-fe:v1.6 .재발 방지
배포 환경별 빌드 스크립트 분리 문서화. 또는 nginx에서 런타임 환경변수 주입 방식으로 개선 예정.
OCI 인스턴스에서 Podman 배포 후 외부 접근 불가. localhost는 정상.
원인OCI는 Red Hat 계열 OS로 Podman 기본. nftables FORWARD 체인에
reject with icmp type host-prohibited 규칙이 컨테이너 포워딩 차단.
sudo nft flush ruleset sudo netfilter-persistent save재발 방지
OCI 인스턴스 초기 설정 가이드 문서화: iptables/nftables 동시 동작 확인, Security List Source Port All 설정, Podman daemonless 특성 명시.
StatefulSet을 직접 다뤄보고 싶어서 PostgreSQL, Kafka, Debezium을 모두 Kubernetes 클러스터 내에 구성했습니다. 그러나 서비스 간 의존성이 깊어질수록 단일 장애 지점(SPOF)이 생기기 쉽고, 특히 Kafka 쿼럼 실패나 PostgreSQL securityContext 오류처럼 하나의 컴포넌트 문제가 전체 서비스에 영향을 미치는 상황을 경험했습니다.
가용성과 보안성을 높이기 위해 StatefulSet 사용을 지양하고, DB + Kafka + Debezium을 별도 VM에 구성한 뒤 Tailscale VPN으로 K8s 클러스터와 묶어 관리하는 방식으로 개선하고 싶습니다. 이렇게 하면 인프라 레이어와 애플리케이션 레이어가 분리되어 장애 격리와 독립적인 스케일링이 가능해집니다.
침수사고 예방 시스템
지하차도 침수사고 예방을 목표로 아두이노 기반 차량 통제 및 지도 알림 시스템을 제작했습니다. 팀장으로서 아두이노 센서 제어, 카카오 MAP API 연동, 실시간 데이터 처리 로직 설계를 주도했습니다. 캡스톤 이후 실시간성 문제를 개선하여 WebSocket 기반 버전으로 발전시켰습니다.
- 🌊 수위/유량 센서 → LED 단계적 경고 (RED→YELLOW→WHITE)
- 🗺️ 카카오 MAP API 침수 위험 지역 마커
- 📍 내 위치 기반 주변 침수 상황 확인
- 📡 HTTP 폴링 → WebSocket으로 실시간 센서 스트리밍
- 🗄️ 임계치 이하 이벤트만 MongoDB Atlas에 기록
- 🔐 /admin 라우팅으로 거리 이력 관리자 확인
초음파 센서 거리값이 라우팅 전환이나 새로고침을 해야만 갱신됨. 실시간 모니터링 불가.
원인HTTP 요청-응답 방식은 클라이언트가 주기적으로 서버에 요청해야 최신값을 받을 수 있음. 아두이노에서 지속 측정되는 센서값을 실시간 반영 불가.
해결Node.js + Socket.io로 WebSocket 양방향 통신 구현. 아두이노 → 시리얼 통신 → Node.js → Socket.io → 브라우저로 실시간 스트리밍. 10cm 이하 이벤트만 MongoDB Atlas에 기록.
새로고침 없이 초음파 센서 거리값 실시간 반영. /admin 페이지에서 최근 50개 이벤트 이력 조회 가능.